During the day, I’m running company called Crisp. We’re building a customer support software used by 500k companies in the world. We distribute a large VueJS Web application that interacts with an HTTP REST API to load conversations, send messages, and much more.
Given the highly distributed nature of our user base, we use Cloudflare Tunnel to serve our HTTP API at low latencies, connecting to our systems running in a single datacenter in Amsterdam. This architecture works great 99.9% of the time. However, traffic between Cloudflare PoPs and our servers transit over the public Internet, which might be subject to packet loss or traffic interruption, or even human error (by Cloudflare or ourselves).
Some context
You may skip this part if you came for the JavaScript code!
The current worldwide geopolitical situation has caused many issues for us in 2024, the worst being around May 2024 when a subsea cable cut in the Red Sea, in addition to an earlier fiber sabotage in a landing point in Marseille, France in 2022, caused the re-routing of a large portion of the Internet traffic between Europe and Asia. Due to the spikes in Internet traffic between those 2 regions at certain times of the day, links became congested, which resulted in very high packet loss between our EU servers and most locations in Asia.
Yes, I was as surprised as you right now, when I learned that a large portion of European Internet traffic with Asia takes the same route, with no proper geographical redundancy.
During hours where EU-Asia paths were congested, Crisp customers in Vietnam to Singapore were unable to reliably access their Crisp apps because:
- Some HTTP requests to Crisp API got back to them with 529 and other 5xx HTTP errors
- Some HTTP requests took 10s and more to complete (although they succeeded!), sometimes hitting a client timeout
Much more recently (last week), an over-night maintenance in the Cloudflare AMS PoP to which our Cloudflare Tunnel agents are connected resulted in a total worldwide outage of Crisp applications, lasting 2 hours (!!), with no immediate remedy. Cloudflare’s control plane stubbornly served our Clouflare Tunnel agents with AMS PoP during the maintenance (!!!), while we expected them to direct our tunnels to the nearby Frankfurt PoP, which was not under maintenance.
This was too much. Time to work on an emergency Cloudflare bypass for our apps.
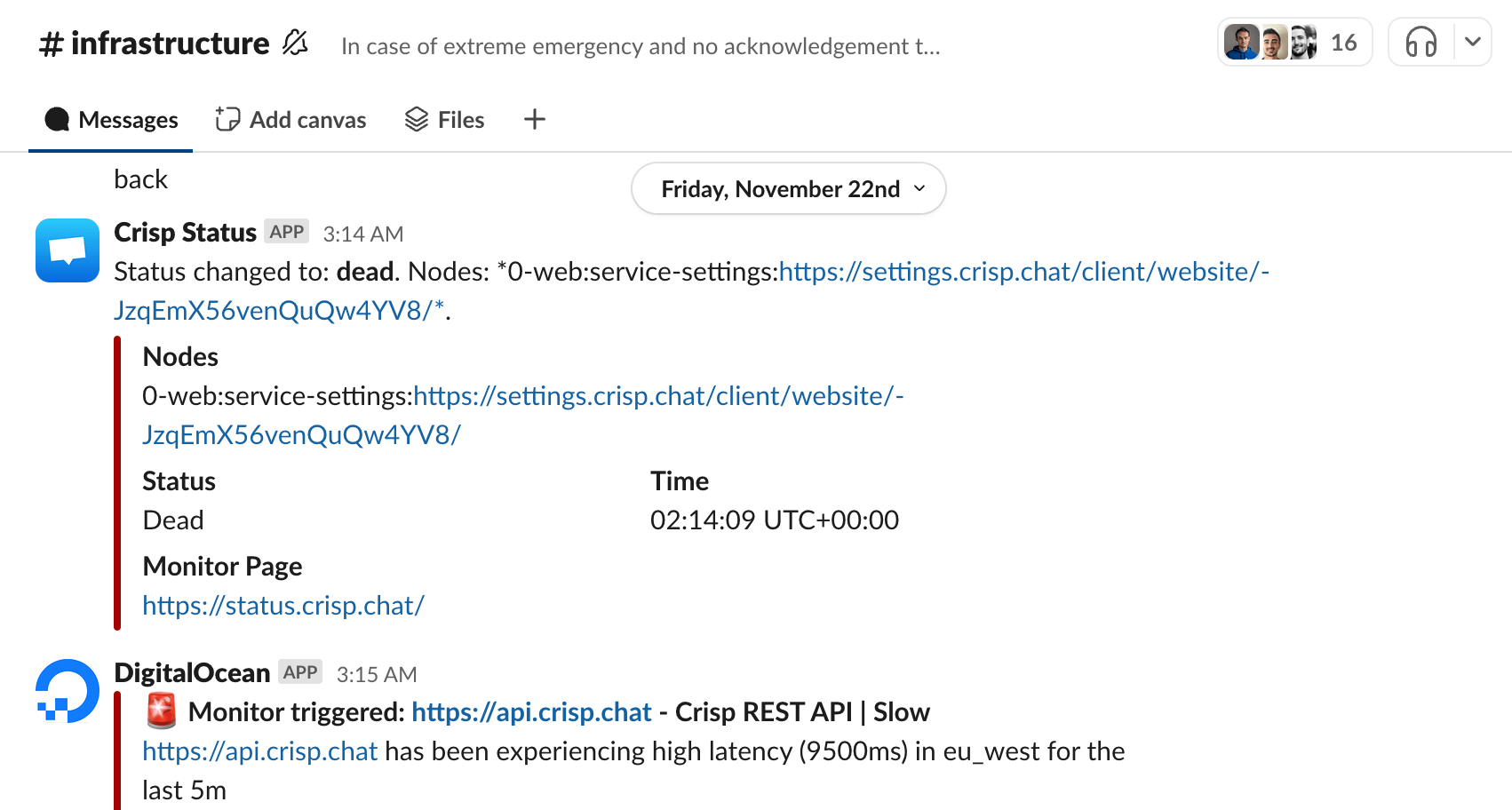
Cloudflare Tunnel, I still love you! Despite all the issues described above, Cloudflare Tunnel is still an amazing product that serves well our needs and just works fine most of the time. However, it seems to be very sensitive to packet loss. The entire tunnel can suffer performance degradation if the link is not stable, resulting in 5xx errors for HTTP clients.
Axios Retry coming to the rescue!
Back in May 2024, in order to solve the situation with customers not being able to access Crisp from Asia and resume service for them, a solution we came up with was to set up a secondary domain to our HTTP API, on a direct NGINX server with a LetsEncrypt SSL certificate. This failover API host would act as a Cloudflare Tunnel bypass.
This would leave us with 2 API hosts:
api.crisp.chatwhich would go through Cloudflare Tunnelrescue.api.crisp.chatwhich would hit a direct NGINX server
Our application would never need to use rescue.api.crisp.chat in normal times, and would always make HTTP requests to api.crisp.chat since it’s lower latency and more secure. In the event of a downtime of api.crisp.chat, our application would however retry any failed HTTP request to rescue.api.crisp.chat.
Since we use Axios to make HTTP calls to our REST API, we used the amazing axios-retry plugin. It acts as a response interceptor on the top of your Axios client, retrying any failed request, for the desired number of times. This means that you do not need to make any change to your existing source code. You can also define on which conditions to retry a request, for instance on which HTTP status code.
In our case, we wanted to retry any idempotent HTTP request once, and at the same time opportunistically change the API host from the main host to the failover host.
We came up with this simple code:
const HTTP_RETRY_ATTEMPTS = 1; // Retry failures once
const HTTP_RETRY_DELAY = 500; // Wait 1/2 second between retries
const HTTP_RETRY_STATUS_FROM = 502; // Retry HTTP 502 to...
const HTTP_RETRY_STATUS_TO = 599; // HTTP 599
// Retry idempotent methods, DO NOT retry POSTs since they could result in \
// same resources being created multiple times in the database, or a message \
// being sent twice or more.
const HTTP_RETRY_METHODS = ["get", "head", "options", "put", "delete"];
axiosRetry(this._client, {
retries: HTTP_RETRY_ATTEMPTS,
retryDelay: () => {
return HTTP_RETRY_DELAY;
},
retryCondition: (error) => {
let _status = error?.response?.status || -1;
// Important: we want to retry requests when we get a status code \
// that indicates the error occurred at the edge (ie. Cloudflare) \
// rather than at the origin. We DO NOT want ot spam our origins \
// with retries here (origin 5xx are transformed to 408). This \
// mechanism helps 'fixing' most temporary communication errors \
// between Cloudflare edges and Crisp origins due to temporary \
// cross-region traffic flow interruptions (eg. backbone \
// congestion). Also, we want to retry requests for which we got no \
// response at all, because of a possible network timeout.
if (
_status === -1 ||
(_status >= HTTP_RETRY_STATUS_FROM &&
_status <= HTTP_RETRY_STATUS_TO)
) {
let _method = error.config?.method || null;
// Ensure we know the method (since we only want to retry idempotent \
// requests)
// Notice: some non-idempotent requests may also be marked as \
// retriable, meaning they can safely be retried.
if (_method !== null && HTTP_RETRY_METHODS.includes(_method)) {
// Do retry this request
return true;
}
}
// Do not retry by default
return false;
},
onRetry(retryCount, _, config) {
// Use different API host? (for next and last retry request)
if (retryCount === HTTP_RETRY_ATTEMPTS) {
// Change next base URL to use (roll in circle)
config.baseURL =
(config.baseURL !== CONFIG.CRISP_URL_API_FAILOVER)
? CONFIG.CRISP_URL_API_FAILOVER
: CONFIG.CRISP_URL_API;
}
},
// Important: reset timeout between retries, since we may want to retry \
// after a timeout occurred on the main API endpoint, although the \
// failover would answer to the same request with no issue. This fixes \
// retries not firing if the first request timed out at the network \
// level.
shouldResetTimeout: true
});
Cool! Testing retries locally involved adding some Math.random() to our backend code and sending random simulated HTTP 529 responses. Our application performed well and retried failed requests transparently, hitting the failover API as expected.
Note that if an intercepted HTTP response has no status code (we set it to a value of -1 in this case), it means that the request has possibly timed out, that is, no response was produced by the server. This may indicate that the user computer is not connected to a network, but it could also be the result of the Cloudflare PoP being too slow to transmit the response from our servers to the end-user, triggering an HTTP client timeout. It is therefore important to retry such failures, due to what I said in the latter point.
It is however super important NOT to retry requests for which we received a response code that indicates a server application-level error. That is, if the HTTP API responds with HTTP 500, it indicates a server error that’s most likely caused by a bug. Retrying the request over a failover network path will produce the same HTTP 500 response, since it is caused by an issue in our API.
Improving user experience during downtimes
While the retry system described above is a very easy and efficient fix to ensure the Crisp application is still usable during a period of downtime of our main HTTP API, in situations where the downtime is prolonged or where the main HTTP endpoint is 100% unreachable, it implies the following:
- The application will work in degraded mode, since non-idempotent HTTP requests will not be retried (POST and PATCH methods), therefore some features might be unusable.
- The application might run considerably slower, if requests timeout after the configured HTTP client timeout of 5s, since
axios-retrywill kick in for a given request after the first request timed out, thus the application UI might take ages to load data. Eg. if you open a conversation or your CRM during a downtime event, some parts of the app might take 10 seconds to load!
Well... the fix might be easy here too… Why not forcing all future requests to the failover HTTP API instead of attempting every single request to the main HTTP API, if we know the main HTTP API is unreachable? And then, maybe later, try restoring the regular HTTP API when we know it’s back up again?
During the 2h total worldwide downtime of our Cloudflare Tunnels in November 2024, we discovered that our simple axios-retry hack from May 2024 was far from perfect. It sometimes worked, it sometimes did not and resulted in an unusable app during the downtime, even if the failover HTTP API was perfectly reachable. While it helped with our packet loss issue between Asia and Europe, in total downtime scenarios it just did not work for us.
We therefore came up with a system that we called “Failover HTTP API lock mode”, consisting of temporarily changing the main HTTP API host to only use the failover host.
Its principles of operation are the following:
- After 3 failed requests (retries triggered) in the last 1 minute then enable full failover mode for the next 10 minutes for all future requests.
- If failure occurs in the same way as explained in point 1 while in failover lock mode, then disable failover mode and use principal URL back again.
- Per-request retries should be performed on principal URL if first attempt uses failover URL (circle back between URLs).
Building up on our existing axios-retry code, we added the following:
We added a global variable to account for retries:
retryCounter = {
startDate: 0, // Timestamp
rollbackDate: 0, // Timestamp
retries: 0 // Counter
};
We modified our onRetry() handler so that it now looks like:
onRetry(retryCount, _, config) {
if (retryCount === HTTP_RETRY_ATTEMPTS) {
// (...existing code here...)
// Bump retry count (this allows entering or exiting failover lock mode)
incrementRetryCounter();
assertRetryCounter();
}
}
Now, we defined some constants based on the principles described above — 3 retries over the last 1 minute, enabling lock mode for the next 10 minutes:
const HTTP_RETRY_LOCK_MODE_ATTEMPTS = 3; // 3 total retries
const HTTP_RETRY_LOCK_MODE_COUNT_TIMEFRAME = 60000; // 1 minute
const HTTP_RETRY_LOCK_MODE_SWITCH_TIMEFRAME = 600000; // 10 minutes
And then we defined the function that increments the global retry counter. This method manages the retry counter and starts the counter again if we passed the 1 minute counting timeframe:
function incrementRetryCounter() {
// Start a new retry counter? (too long since start of counter)
let _dateNow = Date.now();
if (
_dateNow - retryCounter.startDate >=
HTTP_RETRY_LOCK_MODE_COUNT_TIMEFRAME
) {
retryCounter.startDate = _dateNow;
retryCounter.retries = 0;
}
// Increment retry count
retryCounter.retries++;
}
Finally, we defined the method that checks the global retry counter, and switches the base URL used by axios for all HTTP requests, if we need to enter failover lock mode:
function assertRetryCounter() {
// Change main API host? (enter failover lock mode)
if (retryCounter.retries === HTTP_RETRY_LOCK_MODE_ATTEMPTS) {
// Toggle base URL
let _newBaseUrl = toggleBaseUrl();
// Schedule rollback date (we are now in failover lock mode)
retryCounter.rollbackDate =
Date.now() + HTTP_RETRY_LOCK_MODE_SWITCH_TIMEFRAME;
}
}
We also needed a function to toggle the base URL in our axios client:
function toggleBaseUrl(forceDefault = false) {
// This function helps toggle on or off the failover lock mode
let _baseUrl = this._client.defaults.baseURL;
// Acquire new main base URL
let _newBaseUrl =
(_baseUrl !== CONFIG.CRISP_URL_API_FAILOVER && forceDefault !== true)
? CONFIG.CRISP_URL_API_FAILOVER
: CONFIG.CRISP_URL_API;
// Change main URL to failover URL (or back to main URL)
this._client.defaults.baseURL = _newBaseUrl;
// Reset retries counter
// Notice: this is important, otherwise next asserts will never fire a \
// toggle when they should have done so.
retryCounter.startDate = 0;
retryCounter.retries = 0;
return _newBaseUrl;
}
Great! Now, simulating some HTTP 529 failures again from the backend, it was fairly easy to confirm that we entered failover lock mode after 3 failed attempts to the main HTTP API host in the same 1 minute.
But… how do we exit the failover lock mode once the main HTTP API is back online?
The solution we came up with here is to decide whether to exit an active failover lock mode or not whenever making an HTTP request to our API. If we are in failover lock mode and it’s been more than 10 minutes that we entered failover lock mode, we would roll back the base URL used by axios to its default value: our main HTTP API host. If we rolled back to the main HTTP API and all next 3 HTTP requests failed, we would then enter failover lock mode back again.
axios comes up with request interceptors, that let us hook onto any HTTP request that is going to be sent, and run some code before the actual request gets executed. It is the perfect place to restore the regular HTTP API URL once failover lock mode expires after 10 minutes:
// Add request interceptor (automatically gets out of an active failover \
// lock mode)
this._client.interceptors.request.use((request) => {
// Check if should rollback an active failover lock mode
assertRollbackRetryCounter();
// Important: return un-transformed request.
return request;
});
And finally we defined our URL rollback checker function:
function assertRollbackRetryCounter() {
// Should the base URL be toggled from failover back to the main URL?
if (
retryCounter.rollbackDate > 0 &&
Date.now() >= retryCounter.rollbackDate
) {
if (this._client.defaults.baseURL !== CONFIG.CRISP_URL_API) {
// Toggle base URL (force usage of default URL)
toggleBaseUrl(true);
}
// Reset rollback date (not in failover lock mode anymore)
retryCounter.rollbackDate = 0;
}
}
That’s it!
We’ve just improved the resiliency of our application to failed network paths, temporary proxying and tunneling errors and HTTP timeouts, with absolutely no server-side changes.
I’m now waiting for the next downtime to properly test this hardening IRL! 😃
🇫🇷 Written from Nantes, France.